Vol.18 Redis 学习笔记

基本介绍
定义
- 基于内存的分布式的NoSQL数据库
设计
- 所有数据存储在内存中
- 内存数据同步磁盘,实现持久化
功能
- 提供高性能高并发的数据存储, 对外提供读写
- 主要用于数据库存储、数据缓存和消息中间件
特点
- 1.基于C语言开发,读写更快
- 2.基于内存实现数据读写, 性能更快
- 3.分布式的, 拓展性和稳定性更好
- 4.拥有丰富的数据结构
应用场景
- 数据缓存
- 高并发和高性能的大数据量数据缓存
- 数据库存储
- 高并发的小数据量永久性存储
- 大数据架构平台中用于实时计算结果存储
- 消息中间件
- MQ, 传递2个系统之间的数据, 一般不用
RDBMS和NoSQL区别
- RDBMS关系型数据库管理系统
- 工具
- MySQL
- Oracle
- SQL Server
- 应用
- 业务性数据存储系统
- 对事务性和稳定性有较高要求
- 特点
- 1.体现数据关系
- 2.支持完整事务
- 3.保证业务数据完整性和稳定性
- 4.小数据量性能较佳
- 开发
- SQL
- NoSQL 非关系型数据库
- 工具
- Redis Hbase MongoDB
- 应用
- 一般应用于高并发高性能场景下的数据缓存和数据库存储
- 特点
- 1.读写速度特别快,并行量非常高
- 2.不如RDBMS稳定,对事务性支持不太友好
- 3.大数据量
- 开发
- 有自己独有命令语法
主要解决问题
- 实现读写分离(web后端)
- 读请求
- 不读取MySQL,读取Redis
- 写请求
- 直接写入MySQL
安装部署
Windows版
Linux环境单机版
- 上传解压
- 源码编译
- 修改配置
- 配置环境变量
- 启动与关闭服务端
- 启动与关闭客户端
数据结构
所有数据以KV结构形式存在
- K: 唯一标识符,,固定为String类型
- V: 真正存储的数据, V可以有多种数据类型
理解
- 类似于java中的Map集合, 可以存储多个KV,根据K获取V
- Map<String,Object>
数据类型
String字符串
Hash键值对
List有序可重复集合
Set无序唯一集合
Zset有序唯一集合
BitMap位图
- 一般用来做过滤器
HypeLogLog类似set集合
- 一般用于大数据+允许有误差的统计
通用命令
- keys 通配符列举当前数据库所有的key
- del key删除
- exists key判断是否存在
- type key获取V数据类型
- expire key sec单位设置过期时间
- ttl key 查看存活时间
- select N切换数据库
- move key N移动到其它数据库
- flushdb清空当前数据库
- flushall清空所有数据库
数据类型命令
String
- set新增更新对象
- get获取对象
- mset新增更新多个对象
- mget获取多个对象
- setnx新增对象
- incr数值型字符串自增,默认步长1
- incrby key 指定步长数值型字符串自增
- decr数值型字符串自减,默认步长1
- decrby key 指定步长数值型字符串自减
- incrbyfloat key 指定步长浮点型字符串自增
- strlen统计字符串长度
- getrange key 开始位置 结束位置截取字符串
Hash
- hset设置更新V的属性
- hget获取V的某个属性值
- hmset设置更新V的多个属性
- hmget获取V的多个属性值
- hgetall获取V的所有属性和值
- hdel删除V的多个属性
- hlenV的属性数量
- hexists判断V的某个属性是否存在
- hvals获取V的所有属性的值
List
- lpush新数值在左边
- rpush新数值在右边
- lrange key 开始位置,结束位置(0,-1)表示查询所有
- llen获取V长度
- lpop从左边弹掉
- rpop从右边弹掉
Set
- sadd添加更新元素
- smembers查询V的所有成员
- issmembers查询V中是否有该值
- scrm删除V中的某个成员
- scard获取V的成员数量
- union key1 key2取并集
- sinter key1 key2取交集
Zset
- zadd key 评分 V值1…
- zrange [withscores]按照评分升序获取V的元素
- zrevrange [withscores]按照评分降序获取V的元素
- zrem删除V的某个元素
- zcard获取V的元素个数
- zscore获取V的某个元素的评分
BitMap
- setbit修改某一处的值
- getbit查看某一处的值
- bicount key 开始位置字节 结束位置字节统计位图中所有1的个数
- bitop 运算规则 目标对象 bit1 bit2
HypeLogLog
- pfadd添加
- pfcount统计
- pfmerge 目标对象 计算对象1 计算对象2 合并对象
数据持久化
数据存储设计
- 硬盘存储
- 大 安全 读写慢
- 解决方案: 冗余备份, 硬盘RAID
- 内存存储
- 小 易丢失, 不太安全
- 解决方案: 记录日志, 拍摄快照, 副本机制
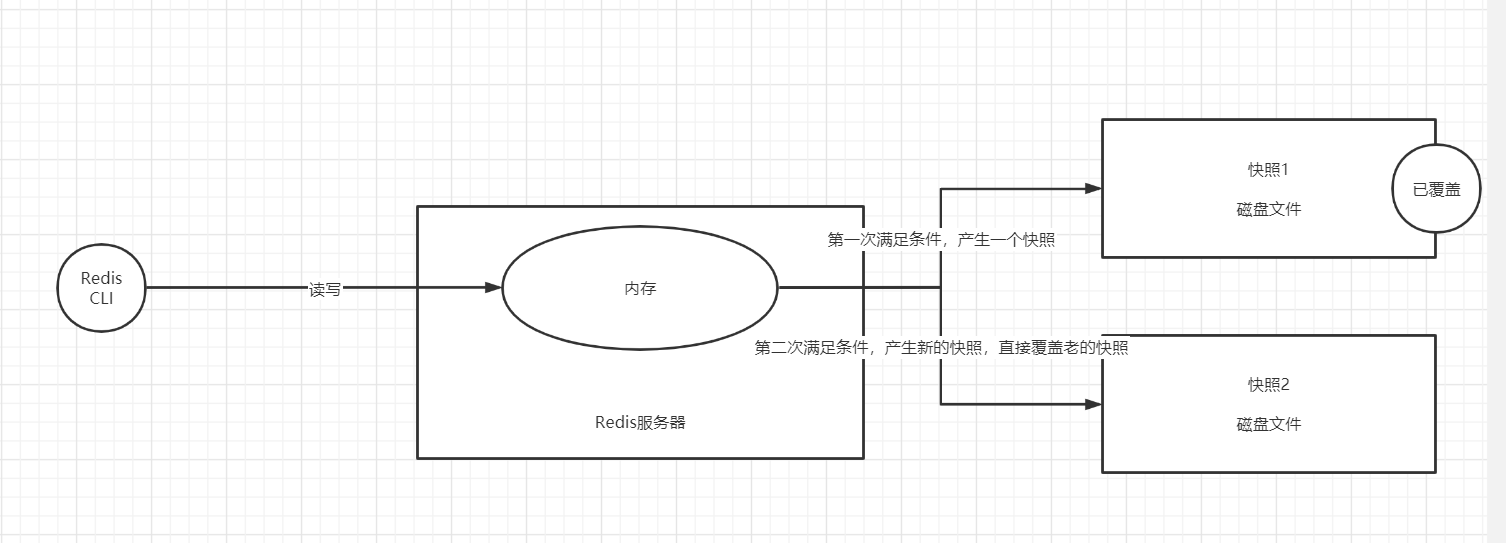
RDB方案
- Redis默认的持久化方案
- 思想
- 一定时间内, 数据更新(新增,修改,删除)一定次数, 拍摄全量快照
- 新快照覆盖老快照, 全量快照, 数据基本和内存一致
- 如果Redis故障, 从硬盘快照文件恢复
- 过程示意图
- 触发
- 手动触发: 执行命令拍摄快照
- save前端运行
- 阻塞所有客户端请求
- 特点: 数据不会丢失, 用户请求会被阻塞
- bgsave后台运行
- fork一个子进程负责拍摄快照
- 客户端可以正常请求
- shutdown执行关闭服务端命令
- flushall清空没有意义
- 自动触发: 一定时间内一个更新次数,拍摄快照
- 配置文件修改save 900 1
- 默认3组, 交叉覆盖,满足不同策略
- 优点
- 1.全量快照, 数据和内存基本一致
- 2.快照二进制, 拍摄快,读取快,体积小
- 3.fork进程实现, 性能更好
- 总结: 更快 更小 体积小
- 缺点
- 存在一定概率导致部分数据丢失
- 策略不可能100%覆盖所有场景
- 应用
- 希望有高性能读写,不影响业务,又允许一部分数据存在概率丢失
- 大规模的数据备份和恢复
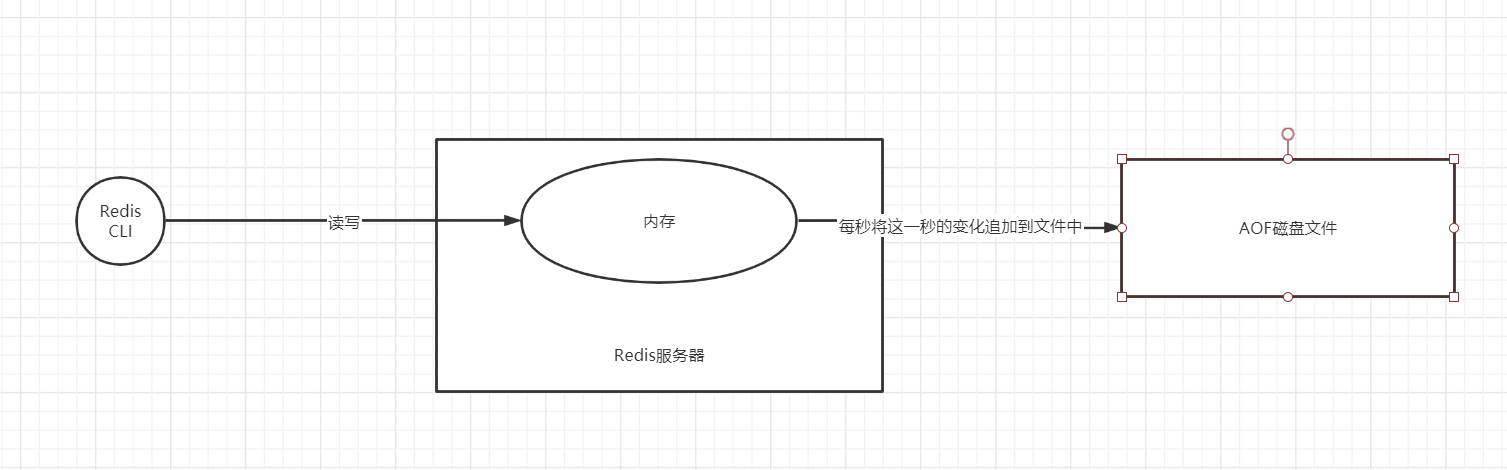
AOF方案
- 思想
- 按照一定规则, 将操作日志追加写入文件
- Redis故障重启,读取日志文件, 恢复数据
- 重新对Redis执行操作, 恢复内存数据
- 过程示意图
- 可选方案
- appendfsync always
- 每更新一条就同步追加
- 优点: 相对安全, 几乎不出丢失数据
- 缺点: 频繁写入,增加IO 性能较差
- appendfsync everysec
- 每秒异步追加到文件
- 优点: 安全性和性能做了权衡, 性能比always高
- 缺点: 有数据丢失风险, 但最多1S
- appendfsync no
- 操作系统控制
- 肯定不使用
- 优点
- 1.安全性和性能做了折中方案
- 2.提供灵活的机制
- 3.对性能要求不高, 安全性可以达到很高
- 缺点
- 1.文件是普通文本文件, 追加写入和加载比较慢
- 2.数据追加写入AOF文件,文件体积增大, 会有过期数据
- 如何解决?
- 模拟类似RDB做全量的方式, 定期生成一次全量AOF文件覆盖旧文件
- 应用
- 数据库或缓存, 运行时的数据安全保障
- 数据持久化安全方案
- 理论上绝对性保证数据否安全
生产文件持久化方案选择
- AOF+RDB
- AOF保证运行时数据安全
- RDB用于辅助构建数据备份
- 一起使用, Redis加载AOF文件
Redis的事务机制
事务定义
- 数据库操作的最小单元, 原子性,一致性, 隔离性,持久性
Redis的事务(一般不用)
- 本身单线程, 没有事务概念
- 支持事务的本质是一组命令的集合, 串行执行
- 命令放入队列, 提交事务串行执行
- Redis事务就是一次性顺序排他执行队列中一系列命令
- 没有隔离性: 没有事务交叉, 不存在脏读幻读
- 不能保证原子性: 单条命令原子性执行,没有回滚机制,命令失败,其它命令正常进行
过程
- 开启事务
- 提交命令
- 执行事务
命令
- multi开启事务
- exec执行事务
- discard取消事务
- watch监听
- unwatch取消监听
Redis实现消息队列
- 消息队列概念
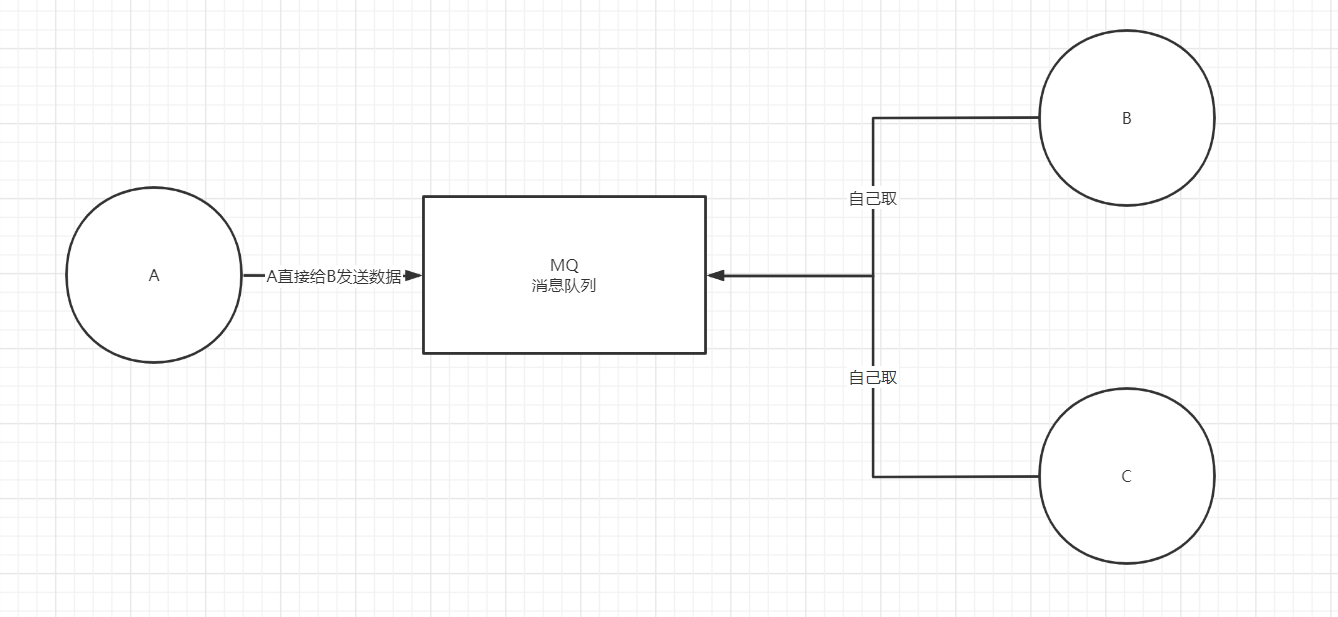
- 如何实现
- publish广播生产消息
- subscribe订阅消息
- unsubcribe取消订阅
过期策略
- 设计思想
- 避免内存满, 指定key存活时间, 时间到自动删除
- 不同策略
- 定时过期
- 指定key存活时间, 监听存活时间, 时间到了自动删除
- 需要CPU一直监听, CPU消耗严重
- 惰性过期
- 指定key存活时间, 使用的时候判断是否过期
- 如果没有使用, 就不会发现过期, 资源浪费
- 定期过期
- 每隔一段时间检查是否过期, 如果过期就删除
- 中和的策略机制
- 生产环境
- 惰性过期和定期过期共同作用
内存淘汰机制
- 概念
- Redis用于缓存的内存不足时,如何处理新写入且需要资源空间的数据
- 5种机制
volatile lru设置了过期时间的key最少使用的key
allkeys lru所有的key中最少使用的, 推荐使用
volatile random设置了过期时间的key中随机选择
allkeys random所有的key中随机选择
volatile ttl根据存活时间
- 生产环境应用
- maxmemory-policy allkeys-lru,移除最近最少使用的key
- allkeys lru缓存使用
- volatile lru数据库使用
Redis架构
zookeeper的集群
- 功能
- 辅助选举,
- 存储元数据
- 定义
- 分布式协调服务框架, 协助分布式软件解决问题
- 设计思路
- 公平节点
- 1.每台ZK节点存储的数据内容一致
- 2.每台ZK都可以接收客户端读写请求
- Leader: 读写请求, 写只能又它来
- Follower: 处理读请求, 转发写请求
- 3.每台ZK都是资格成为Leader
主从复制集群
- 解决问题: Redis单点故障
- 架构图
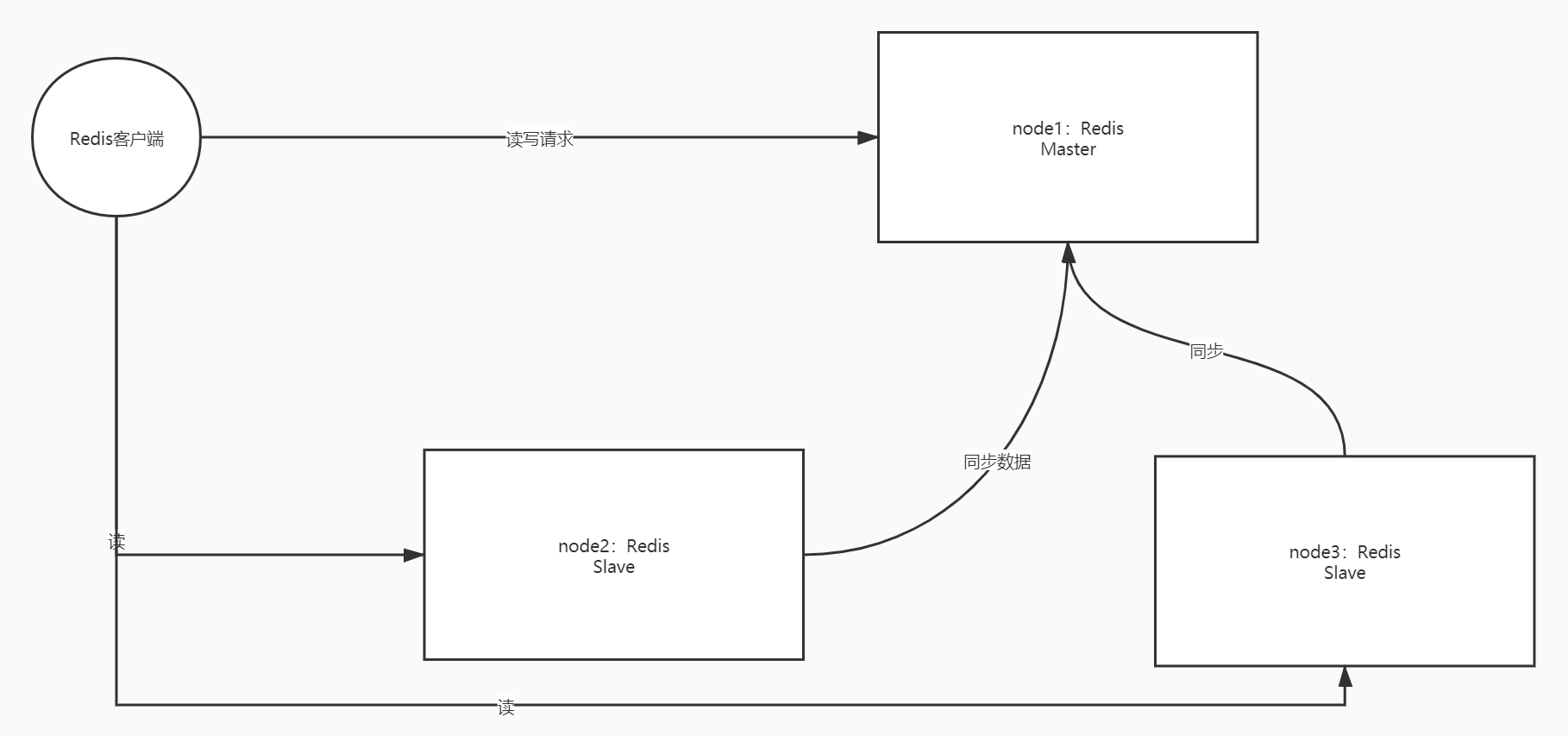
- 设计
- Master主节点
- 对外提供数据读写
- Slave从节点
- 对外提供读请求, 不能接收写请求
- 负责与主节点同步数据
- 特点
- 主从节点数据一致,都可以读, 写只能由Leader来
- 优缺点
- 优点
- 实现读写分离, 分摊压力, Slave挂了问题不大
- 缺点
- Master挂了, 集群不能提供写请求
- 同步策略
- 全量同步
- 新Slave节点或者长时间没有链接
- bgsave构建内存闪照, Master维护缓存队列
- 全量同步比较消耗性能
- 增量同步
- Master将Slave没有的同步的数据放入挤压缓冲区
- Slave请求同步, 判断同步的数据在缓冲区就同步
哨兵集群
- 解决问题: 主从复制集群中Master的单点故障问题
- 架构图
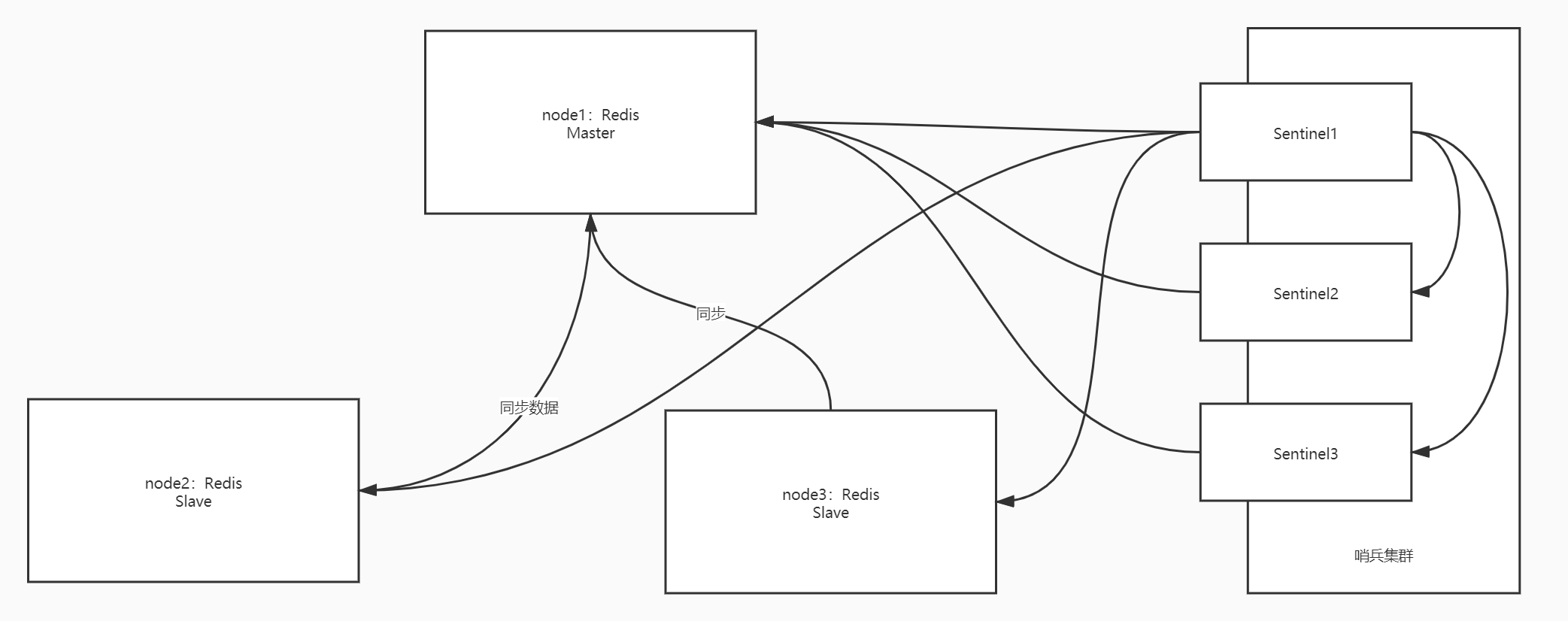
- 设计
- 思路
- 基于主从模式封装哨兵模式, 如果Master发生故障,哨兵选择一个新的
- 实现: 哨兵进程实现
- 必须能够发现Master的故障, 监听Master
- 必须负责重新选举新的Master, 监听所有的Slave
- 保证自己不出问题, 搭建哨兵集群
- 哨兵集群: 多个哨兵节点构建, 彼此互相监听
- 故障分类
- 主观故障
- 某个哨兵报告Master故障
- 客观故障
- 超过一定个数的哨兵认为的Master故障, 才是真的故障
- 实现选举切换
- 功能
- 集群监控:监控节点状态
- 消息通知:汇报节点状态
- 故障转移:实现Master重新选举
- 配置中心:实现配置同步
- 选举流程
- 1.Master发生故障, 某个哨兵发现并报告所有哨兵(主观性故障sdown)
- 2,当一定个数的哨兵认为Master故障, 整体就认为Master故障了(客观性故障odown)
- 3.所有哨兵根据每台Slave通信的健康状况和权重,选举一个新的Master
- 4.将其它Slave的配置文件中的Master切换为最新的Master
分片集群
- 解决问题:单点故障+单台内存过小
- 架构图
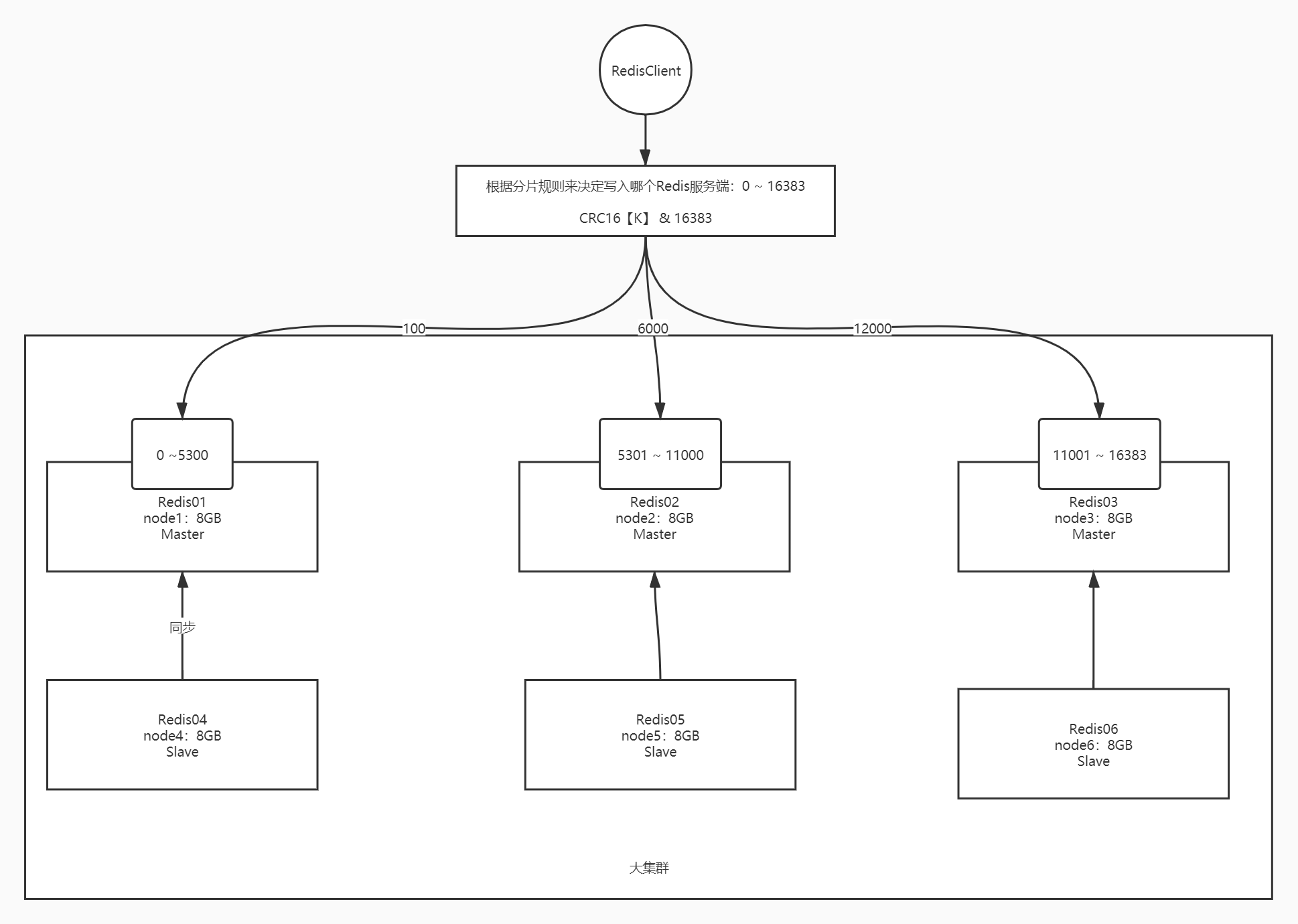
- 设计
- 思想
- 将多个Redis小集群, 逻辑上合并一个大的集群
- 每个小集群分摊一部分槽位,对每一条Redis的数据进行槽位计算
- 判断数据应该存入那个槽位,对应存储到小集群中
- 分片规则(槽位计算):根据key进行槽位计算CRC16 [K] & 16383 = 0~16383
Jedis的使用
类型
- 单机版Linux型
- 主从复制集群
- 读取随机选择
- 写入固定给Master
- 哨兵集群
- JedisSentinelPool
- 分片集群
- JedisCluster
涉及到类
- Jedis客户端连接对象
- JedisPool 连接池对象
- JedisPoolConfig配置文件对象
- JedisSentinelPool哨兵模式连接池
- JedisCluster分片模式连接连接池对象
涉及方法
- 都是类中的方法
流程
- 1.获取客户端连接对象
- 直接创建对象
- 通过连接池获取
- 1.获取并设置连接池配置对象
- 2.获取连接池
- 3.获取连接对象
- 2.测试代码
- 3.释放资源
常见分布式架构
公平节点架构: ZK, Redis
普通主从架构: HDFS, Yarn
- 都需要依赖ZK
Vol.18 Redis 学习笔记
https://jface001.github.io/2023/04/09/vol18-Redis学习笔记/