Vol.10 Spark核心工作原理小记

整理学习 Spark 相关知识的笔记,查缺补漏。不得不说整理的时候重新捡起了很多遗忘的知识,Scala 我也很久很久没有写了, 现在公司用的是 Pyspark ,后面也整理记录下 Pyspark 的相关笔记。
Spark 组件的数据抽象和上下文对象
SparkCore
- 数据抽象: RDD
- 上下文对象: SparkContext
SparkSQL
- 数据抽象: DataFrame DataSet
- 上下文对象 SparkSession
SparkStreaming
- 数据抽象:DStream
- 上下文对象: StreamingContext
StructuredStreaming
- 数据抽象 :DataFrame, DataSet
- 上下文对象: SparkSession
RDD、DataFrame和Dataset 三者的共同点跟区别
三者的共同点
- 都是【分布式数据集】
- 转换操作都是【懒lazy】执行。
- 都支持【持久化】,都支持【12】种缓存策略
- 都支持【checkpoint】
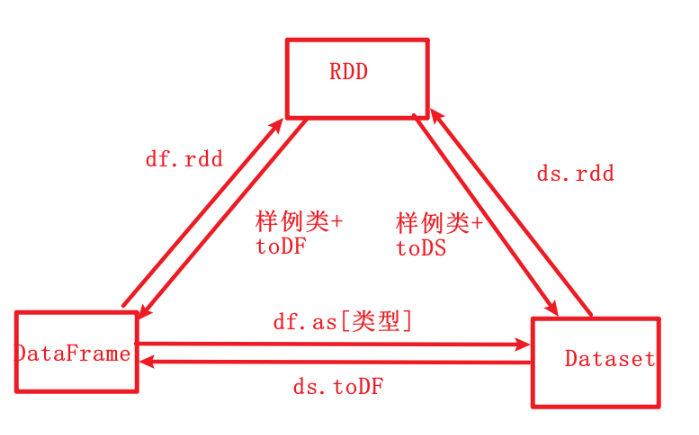
RDD
- 弹性分布式数据集
- 弹性:他的存储和计算的节点可以【扩展】。数据可以存储在内存,如果【内存】不够,可以溢写到【磁盘】。
- 分布式:计算和存储都是分布式的
- 数据集:我们可以像使用scala本地集合一样使用RDD分布式数据集,可以很方便使用【函数式】编程。
- 元素【不可】变,【可】分区,分区间【并】行计算。
- 元素的【泛型】要支持可序列化。反例如 Connection
- 缺点: 集群间的通信效率低,对象的序列化和反序列化开销大,会频繁的创建和销毁对象。
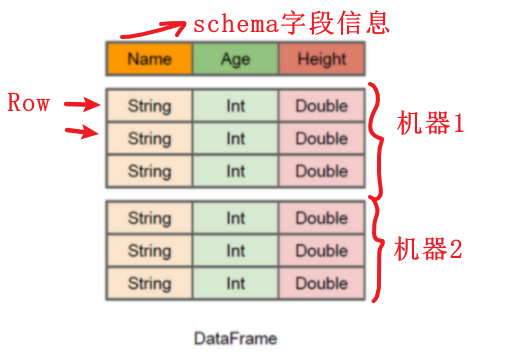
DataFrame
- 在RDD的基础上支持【schema】
- DataFrame=RDD -【泛型】+方便的【SQL】操作+【DSL】操作+【catalyst】优化
- 将【数据】和【schema】分离存储,减小了序列化和反序列化的开销
- 支持catalyst,【RBO】基于规则的优化(【常量折叠】,【谓词下推】,【列裁剪】)和【CBO】(基于代价模型的优化)
- 缺点:DataFrame不能【类型安全检查】:比如dataframe.select(“不存在字段”)这句代码编译【通过】,但是运行时【报错】。
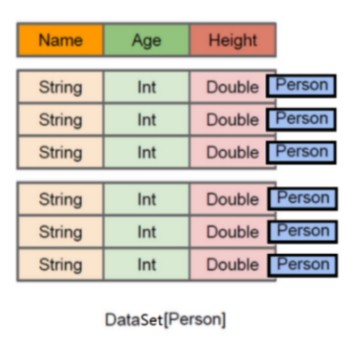
Dataset
- 在DataFrame的基础上支持【泛型】
- Dataset=RDD[泛型]+schema+方便的SQL操作+catalyst优化+Tungsten
- 泛型分为【强】类型和【弱】类型,当类型是弱类型时DataFrame=Dataset[ Row].
- 自动的将样例类(jvm对象)的【属性】映射成分布式表的【字段】
- Dataset具有【类型安全检查】:比如dataset.map(x=>{x.不存在的属性}) ,编译时就报错。
- 直接继承了DataFrame的【catalyst】优化
- 独有【Tungsten】优化,支持特殊的编码器,基于内存管理的优化,使对象的存储更节省空间。
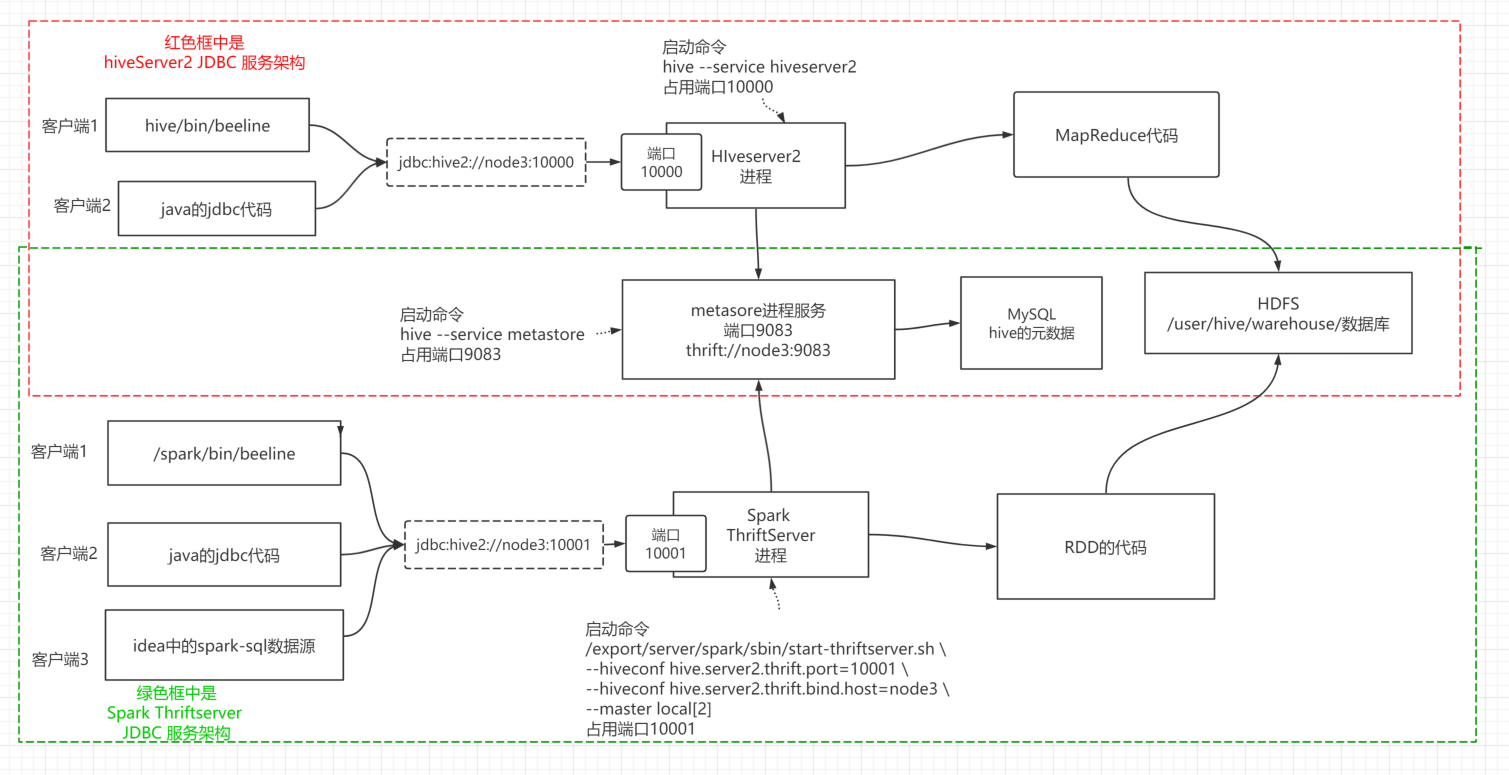
Spark 跟 Hive 的关系
Spark Thriftserver hiveserver2 metastore beeline 的关系
Spark SQL catalyst 优化器
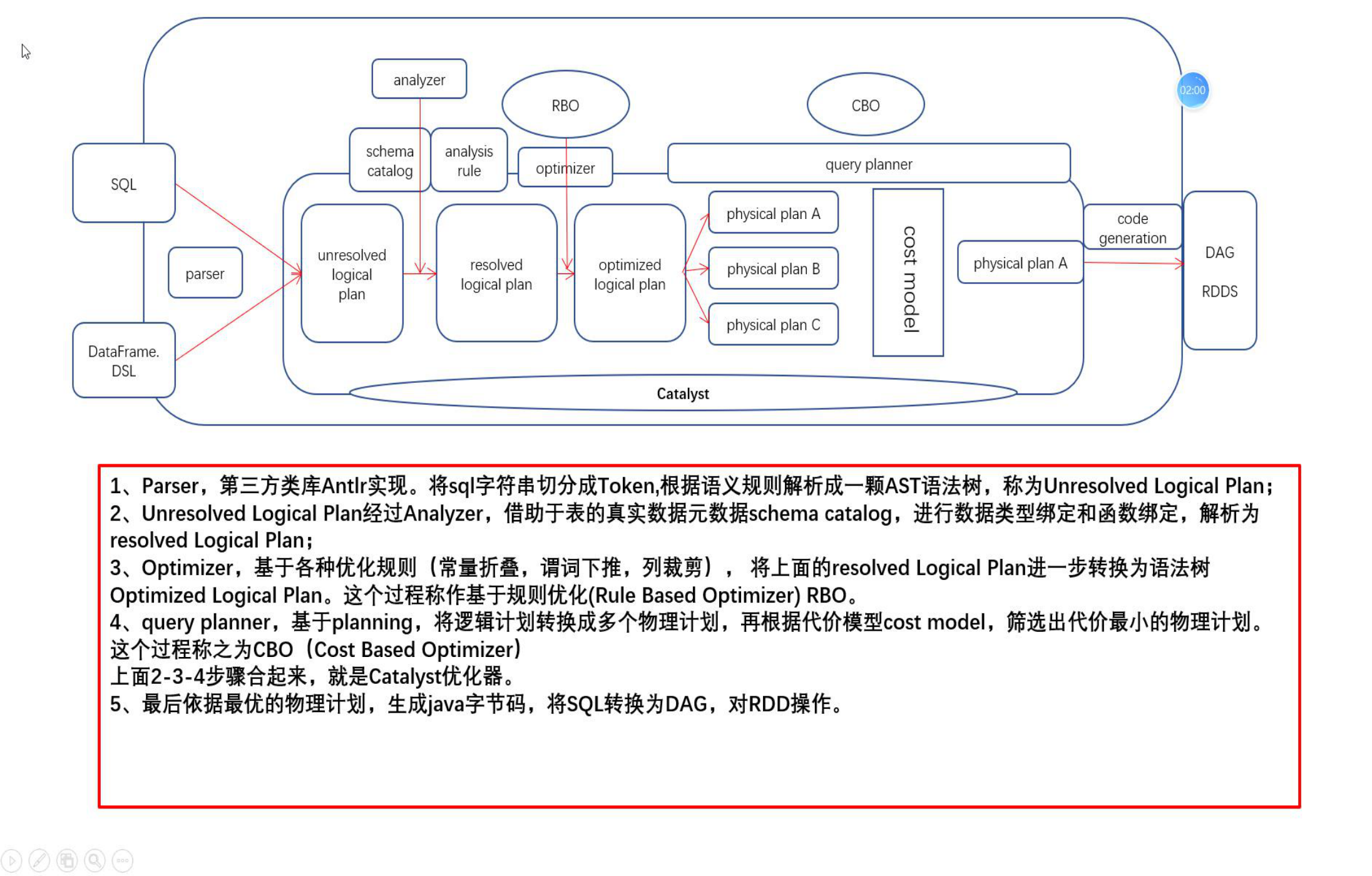
- RBO:基于规则优化
常量折叠:常量提前计算
谓词下推:在表关联前做过滤
列裁剪:只选择需要的列
- CBO: 基于物理消耗的优化
Spark 的两种运行模式
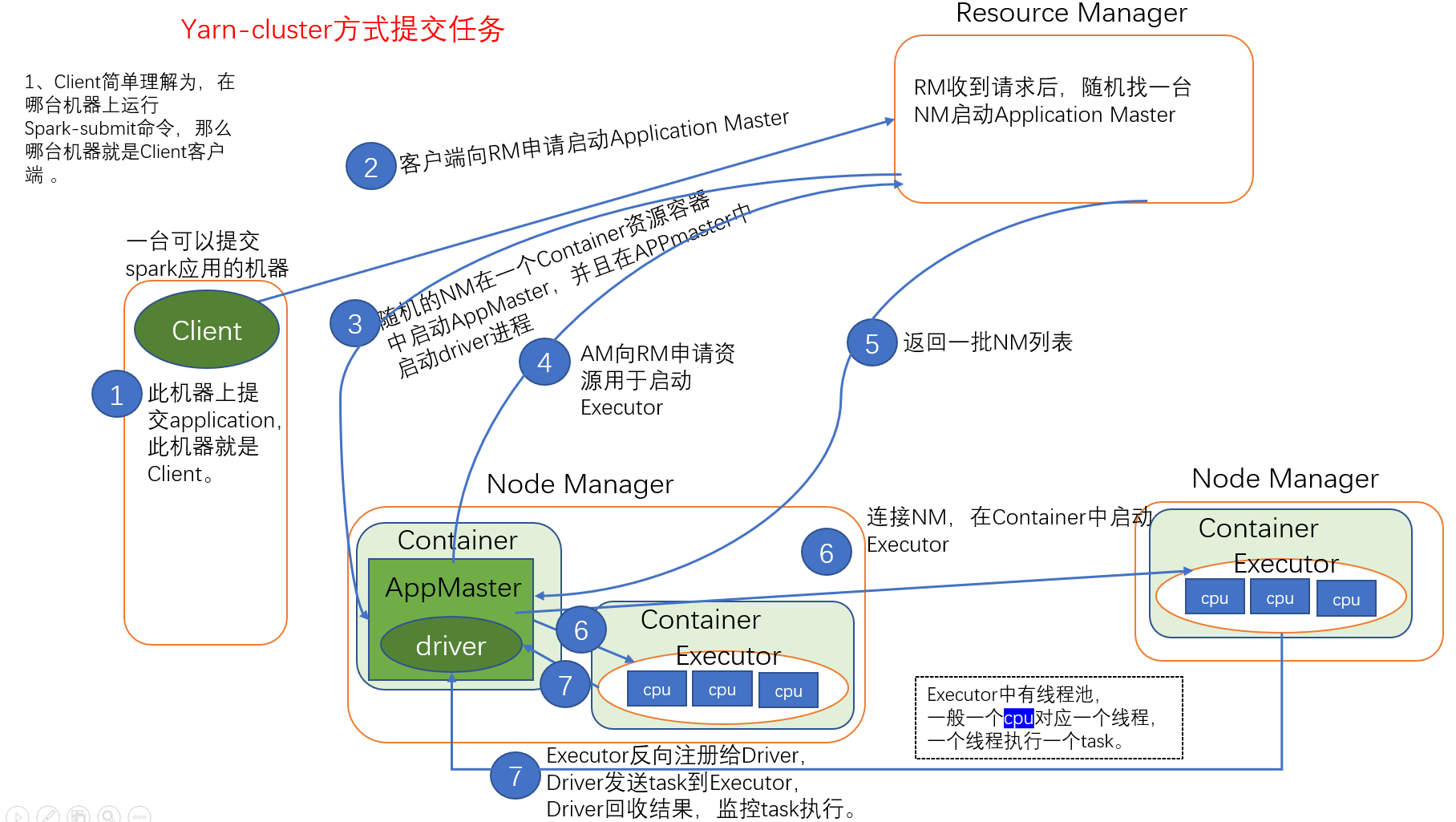
Yarn-cluster 方式提交任务
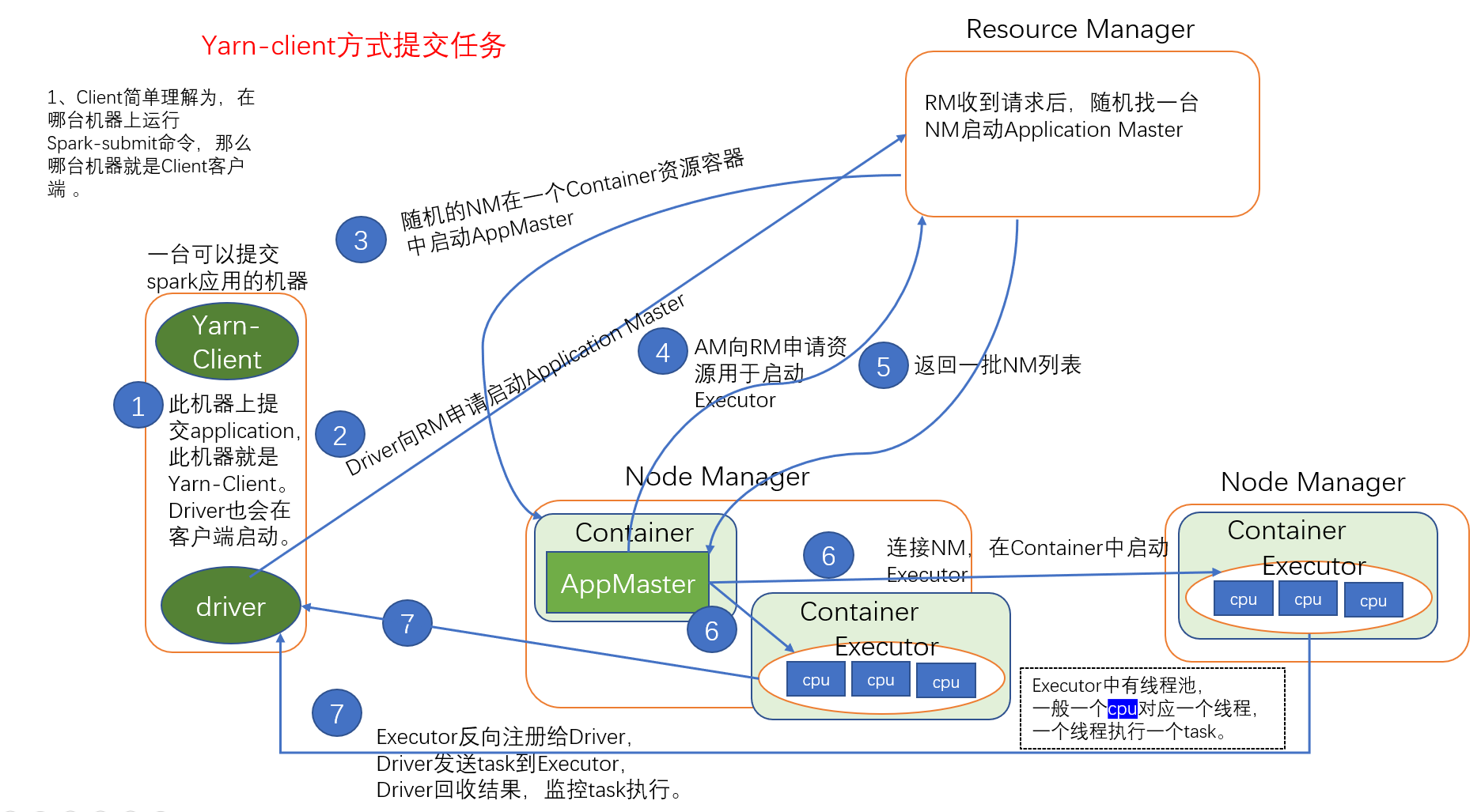
Yarn-client 方式提交任务
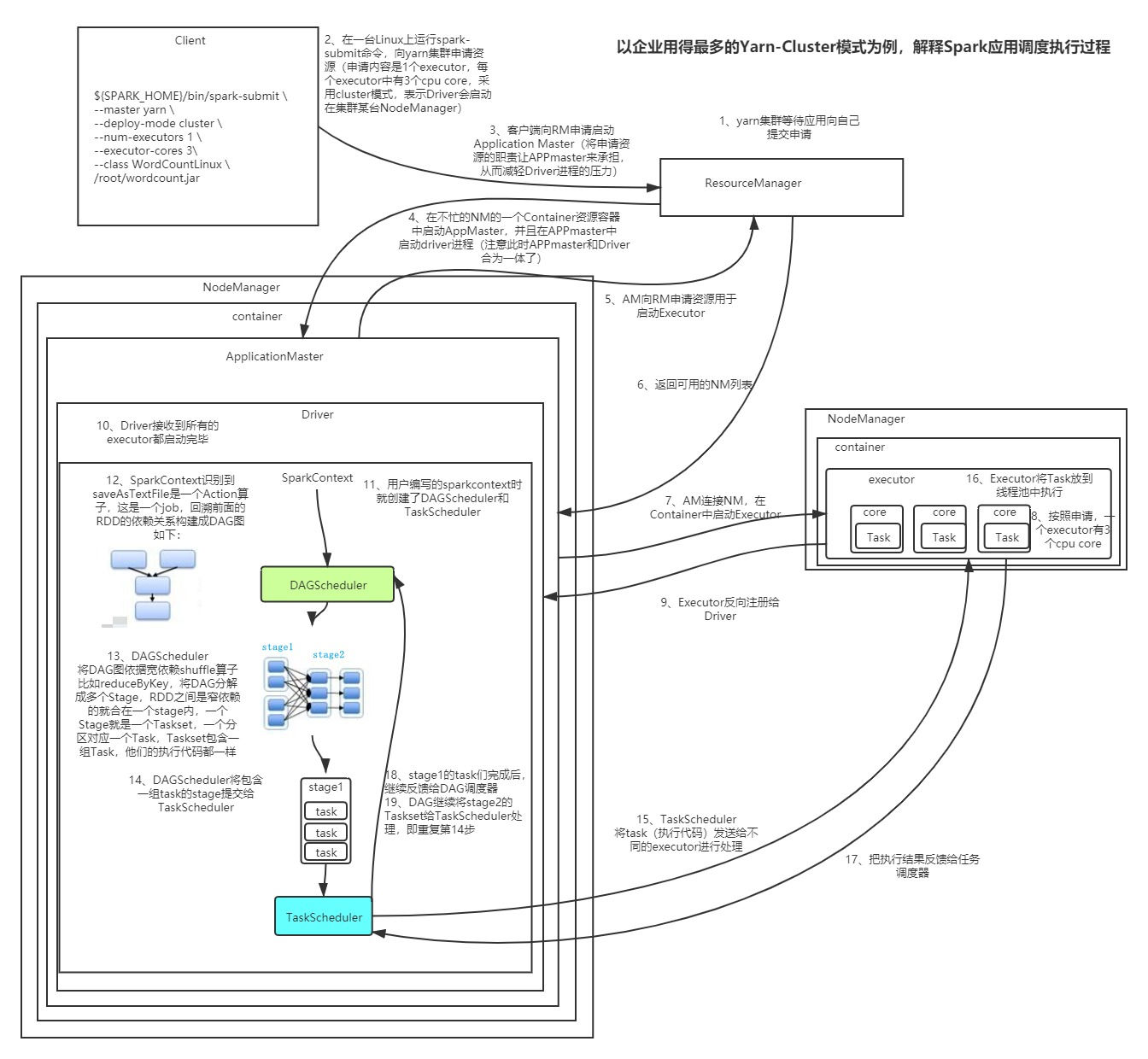
Spark 调度任务执行流程
准备执行
- Yarn集群等等任务提交
- Spark程序执行
- 客户端向RS申请启动APP
- 在NM启动APP,启动Driver进程,合为一体
- APP申请资源
- RS返回可用NM
- APP连接NM并启动Executor
- 按照程序分配资源给Executor
- Executor反向注册给Driver
- Driver确定所有Executor准备完毕
分配任务
- Spark程序SC创建2个调度器对象
- SC识别Action算子DAG
- DAGScheduler切分Stage,将Stage内的Task打包成TaskSet
- DAGScheduler将一个Stage的TaskSet发给TaskSchuster
- TaskScheduler将TaskSet中Task分发给不同Executor处理
执行任务返回结果
- Executor将Task放到线程池执行
- Executor将执行结果返回给TaskScheduler
- 一个StageTask完成后继续反馈给DAGScheduler
- DAGScheduler继续将剩下的Stage发送给TaskScheduler,重复循环,直至完成
Spark Steaming 原理
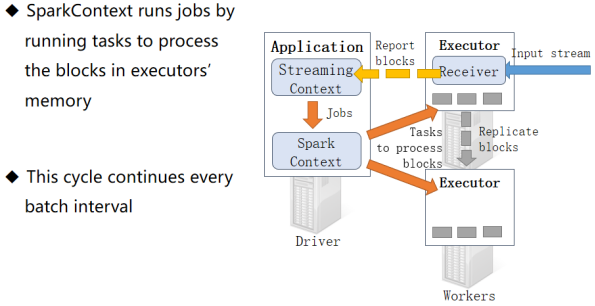
- StreamingContext对象封装了SparkContext对象
- 启动时同时启动Driver Executor
- 一个Executor启动Receiver
- 每到blockInterval时间间隔,就会生成一个数据块,实时同步备份到其它Executor
- blockInterval默认是200ms,可以手动设置spark.streaming.blockInterval最低支持50ms
- 把数据块信息同步给StreamingContext对象, 攒够生成RDD给SparkContext对象
- BatchInterval一般是blockInterval的整数倍,其中每个block是RDD的一个分区
- SparkContext对象分发任务给Executor执行
Structured Steaming 原理
抽象概念
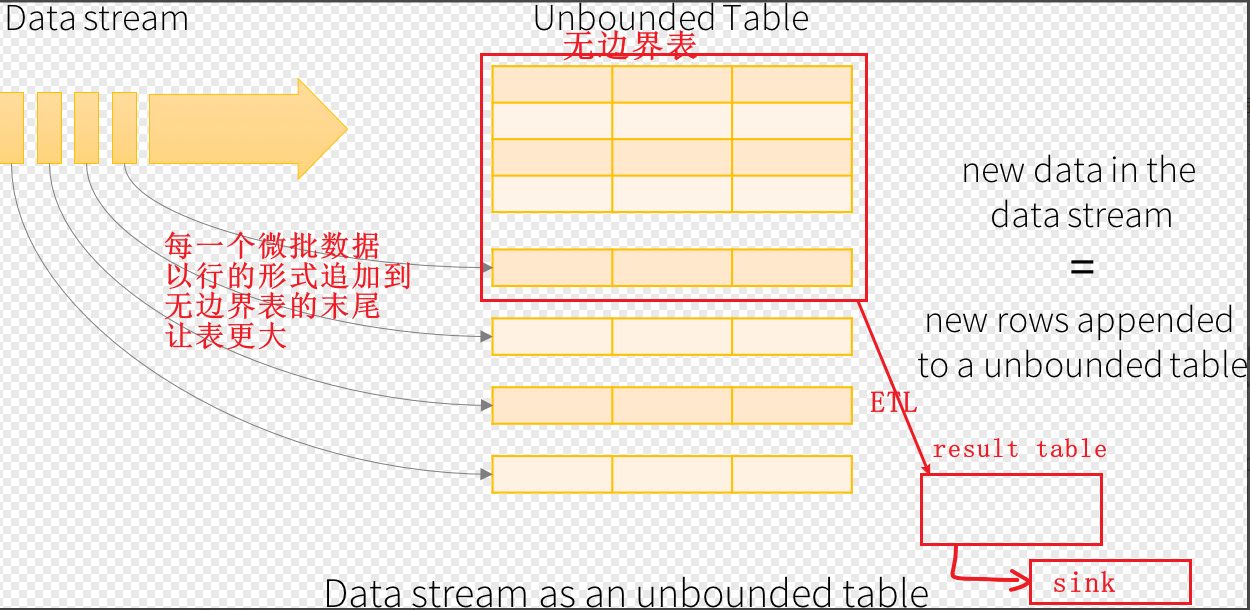
- input table unbounded table无边界表,动态的增加数据,用DataFrame表示
- data stream增量数据, 以行形式追加到unbounded table
- query 查询逻辑,有追加更新立即触发查询
- result table查询结果, 是一个DataFrame
- output结果输出, append complete update三种模式
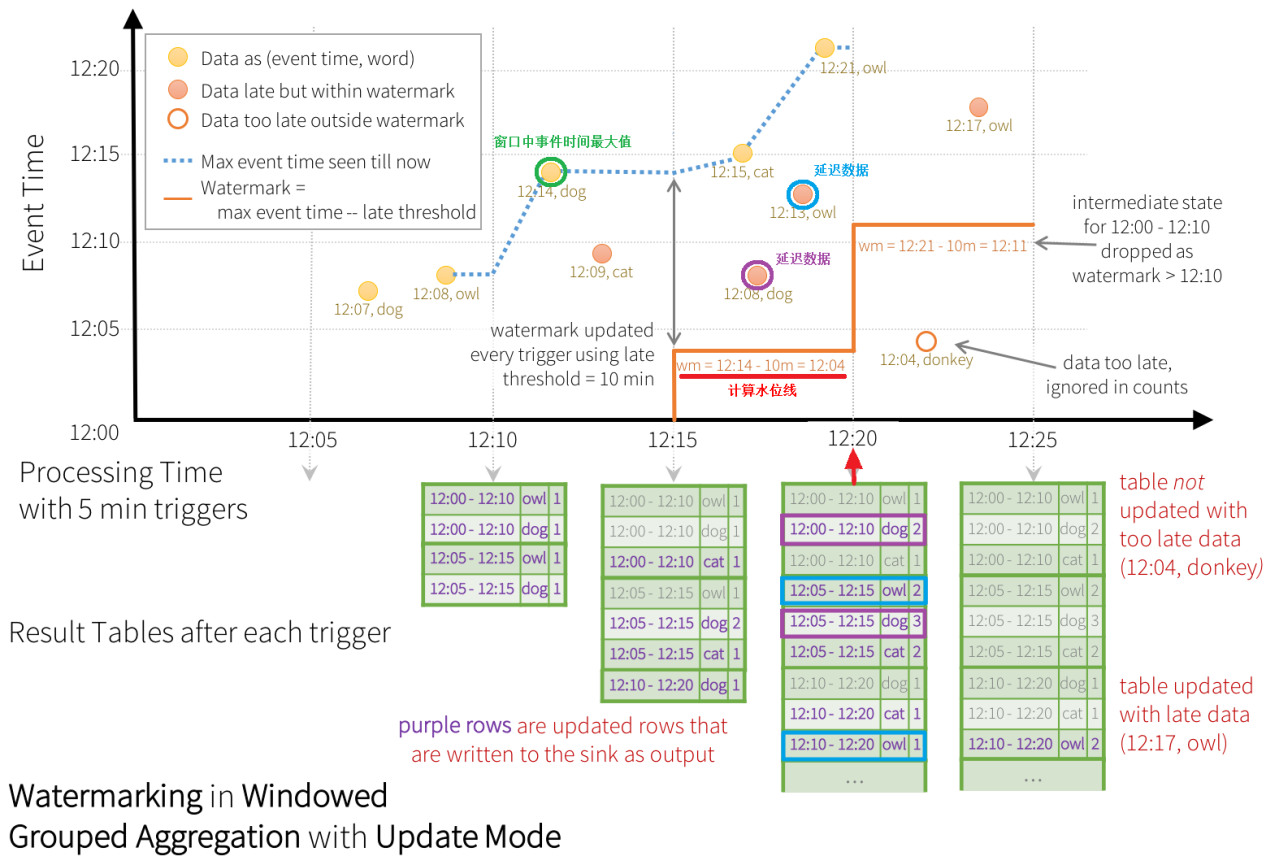
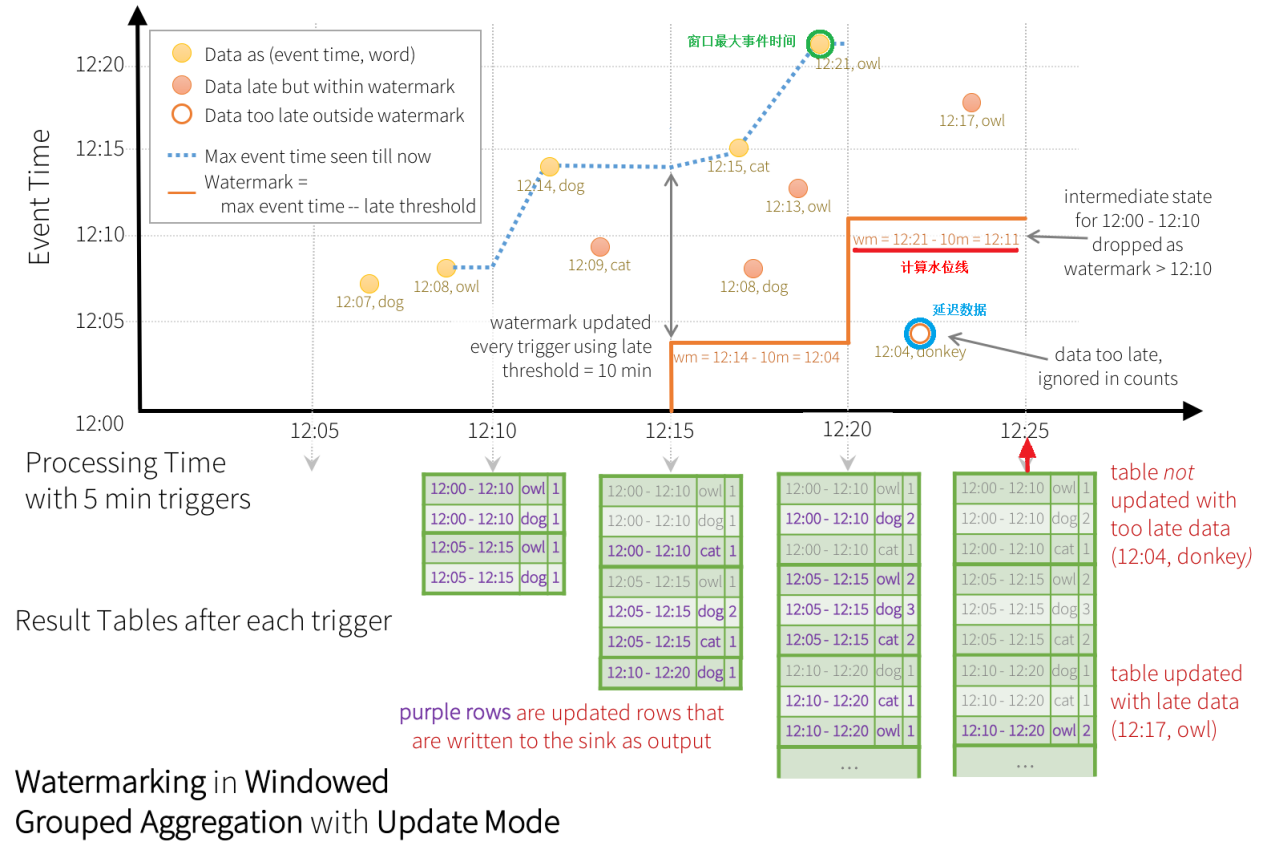
EventTime 事件时间
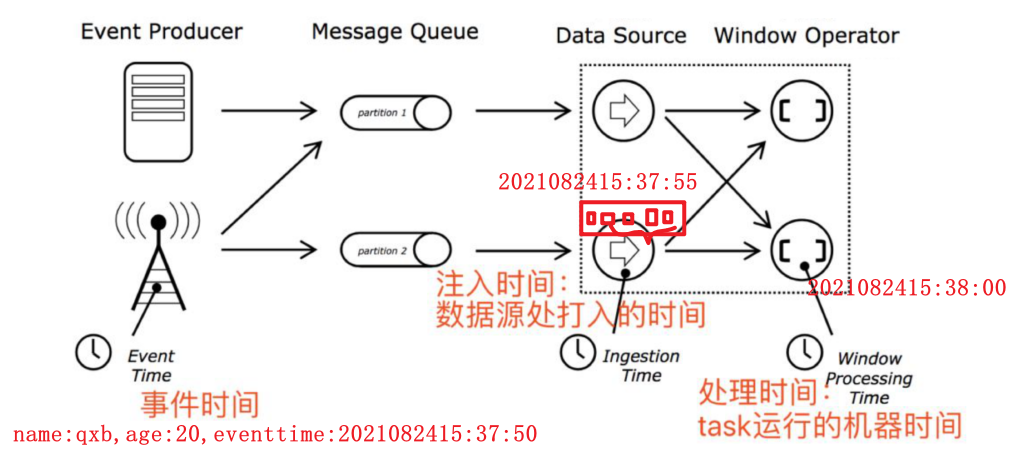
时间的分类
- EventTime 事件时间数据产生的时间
- IngestionTime 注入时间数据到达流式系统的时间
- ProcessingTime 处理时间数据被流式系统真正处理的时间
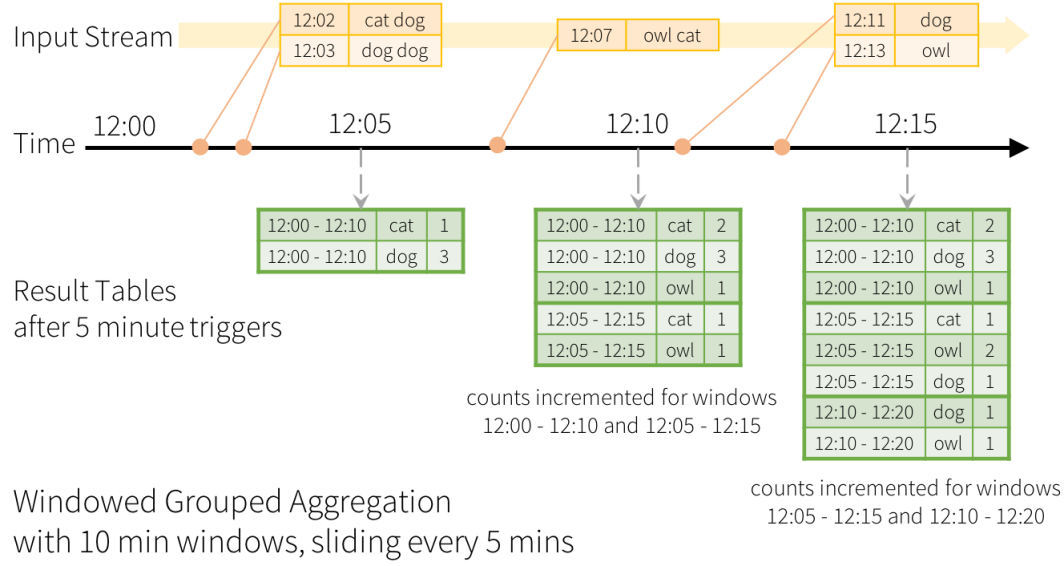
应用场景:基于事件时间的窗口聚合
watermark 水位
公式:Watermark = 【MaxEventTime 】 - 【Threshold】
- MaxEventTime【上】一批次数据中的【最大的eventime值】
- Threshold 预估事件的延迟时间上限
Vol.10 Spark核心工作原理小记
https://jface001.github.io/2023/02/12/vol10-Spark核心工作原理小记/