Vol.09 M1款 MacBookPro 搭建 JupyterLab 数据分析环境

Python 用于数据分析的优势我就不多赘述,虽然当前基本不写 Python,但是我经常需要阅读 Python 代码,看别人写的数据处理逻辑,所以开始进一步学习 Pyspark 相关的知识。Jupyter 应该是学习 Python 数据分析最佳的工具了,趁着刚刚安装完,记录下自己环境配置跟常用的工具。
miniconda 安装
提到 Python 数据分析大家一般推荐 Anaconda,miniconda 属于轻量级的包管理工具,我更推荐使用。在官网现在自己匹配的平台,下载安装即可,也可以选择 homebrew 安装。
https://docs.conda.io/en/latest/miniconda.html
Jupyter Lab 安装
miniconda 安装完成之后,测试 Python 能正常进入,开始 安装 Jupyter 及其拓展插件。
# 本体
pip install jupyterlab
# 格式化插件
pip install jupyterlab_code_formatter
# 格式化检测插件
pip install black isort
# 目录树功能
pip install jupyterlab-unfold
# 中文支持
pip install jupyterlab-language-pack-zh-CN
# GitHub 仓库支持
pip install jupyterlab-github也需要注意下修改登陆密码,跟设置后台启动。
# 进入 Python 交互命令行
from notebook.auth import passwd
# 设置密码,第二次输入密码之后会有一串秘钥,记下来后面配置文件需要用到
passwd()修改配置文件
# 终端命令行输入
jupyter lab --generate-config
# Out
/Users/jface/.jupyter/jupyter_lab_config.py
# 上面文件增加以下 3 行配置,秘钥填入上面设置密码获取到秘钥
c.ServerApp.allow_root = True
c.ExtensionApp.open_browser = False
c.ServerApp.password = '秘钥'设置后台启动
nohup jupyter lab --allow-root > jupyterlab.log 2>&1 &
# & 让命令后台运行,并把标准输出 写入jupyterlab.log中。
# nohup 表示no hang up ,就是不挂起,这个命令执行后即使终端退出,jupyter 也不会停止运行。Spark 安装
Spark 直接使用 homebrew 安装。
# 安装 spark
brew install apache-spark
# 设置环境变量,如果是 zsh 编辑文件 .zshrc,写入安装路径
export SPARK_HOME=/opt/homebrew/Cellar/apache-spark/3.3.1
export PYTHONPATH=$SPARK_HOME/libexec/python:$SPARK_HOME/libexec/python/build:$PYTHONPATH注意如果以下执行文件入口没有权限,需要给他们给到权限
chmod 755 -R /opt/homebrew/Cellar/apache-spark/3.3.1/bin
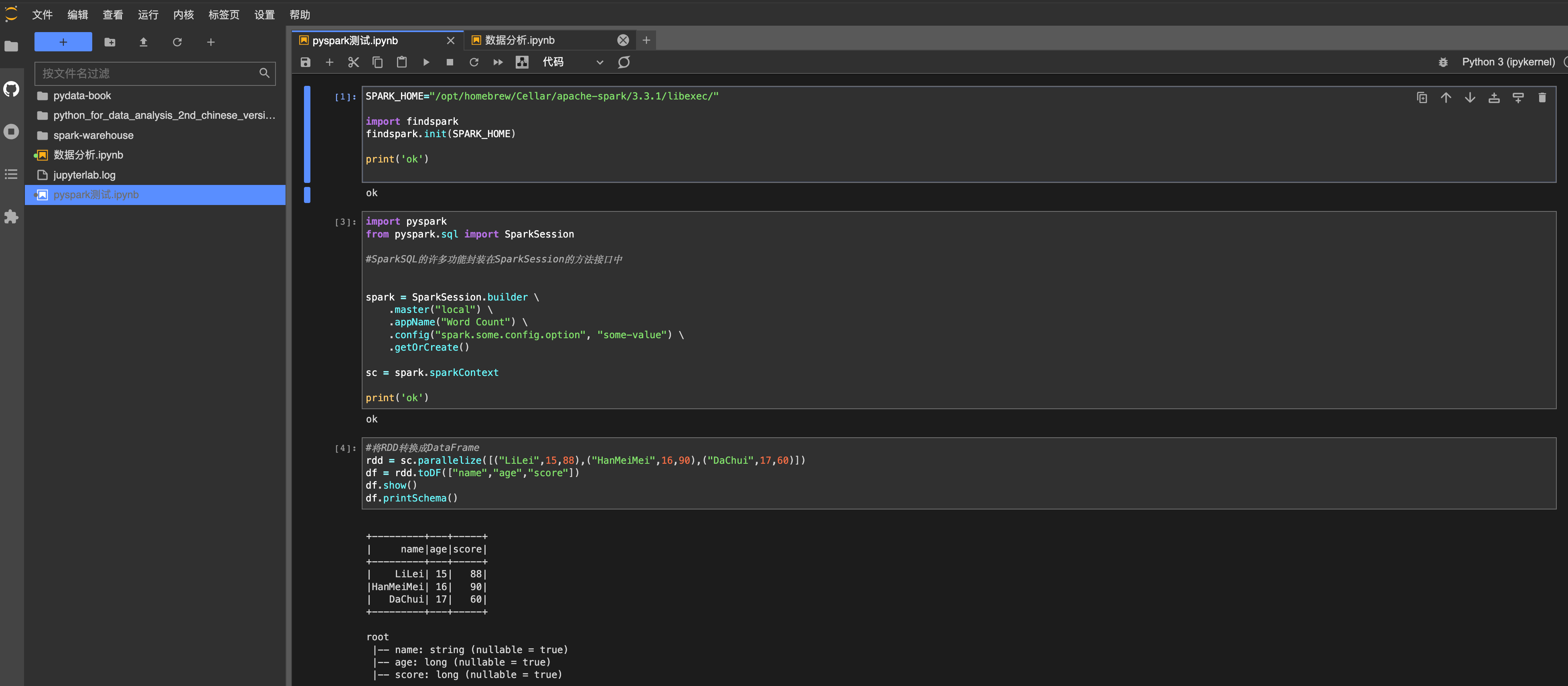
chomd 755 -R /opt/homebrew/Cellar/apache-spark/3.3.1/libexec/binPyspark 入门测试
安装必要的 spark 相关第三方包。
pip install findspark
pip install pyspark实际代码测试
# 载入环境变量,注意 Spark 的执行环境路径,可能不同,下面两个都尝试下
#SPARK_HOME="/opt/homebrew/Cellar/apache-spark/3.3.1/bin"
SPARK_HOME="/opt/homebrew/Cellar/apache-spark/3.3.1/libexec/"
import findspark
findspark.init(SPARK_HOME)
print('ok')
#SparkSQL的许多功能封装在SparkSession的方法接口中
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master("local") \
.appName("Word Count") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
sc = spark.sparkContext
print('ok')
#将RDD转换成DataFrame
rdd = sc.parallelize([("LiLei",15,88),("HanMeiMei",16,90),("DaChui",17,60)])
df = rdd.toDF(["name","age","score"])
df.show()
df.printSchema()
#Out 输出
+---------+---+-----+
| name|age|score|
+---------+---+-----+
| LiLei| 15| 88|
|HanMeiMei| 16| 90|
| DaChui| 17| 60|
+---------+---+-----+
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- score: long (nullable = true)最终效果
数据分析推荐资料
https://www.howie6879.cn/post/2021/26_jupyterlabv2_tutorial-/
https://www.jianshu.com/p/872648f7cc58
https://github.com/wesm/pydata-book
https://github.com/iamseancheney/python_for_data_analysis_2nd_chinese_version
Vol.09 M1款 MacBookPro 搭建 JupyterLab 数据分析环境
https://jface001.github.io/2023/02/05/Vol09-M1款MacBookPro搭建JupyterLab数据分析环境/