Apache Spark:分布式并行计算框架(三)
Spark on Hive
面试题:
spark on hive和hive on spark区别????
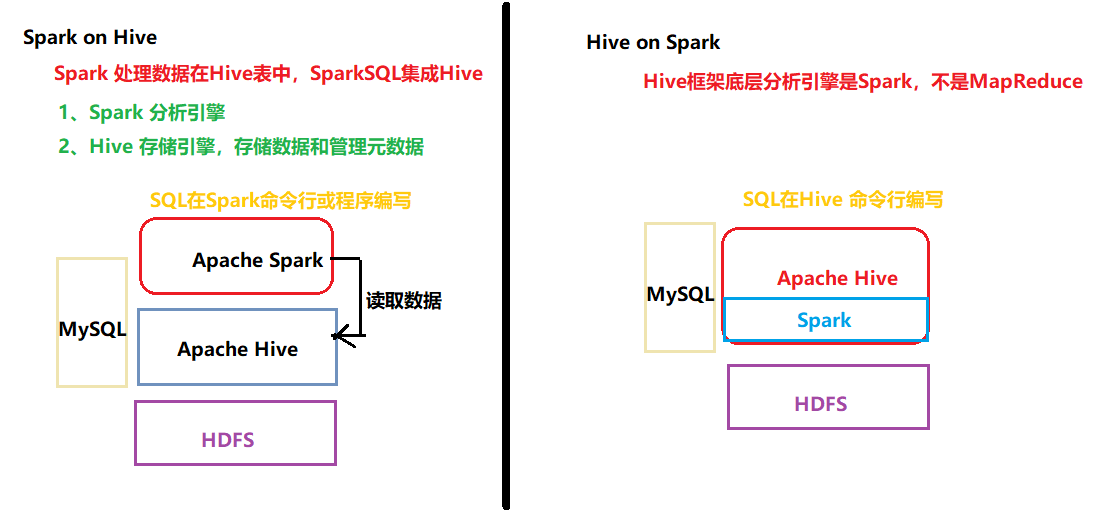
典型基于Spark和Hive离线数仓架构技术图,简易版本:
1、SparkSQL分析数据
2、Hive 管理元数据
|
Spark on Hive 架构,离线数据仓库分析
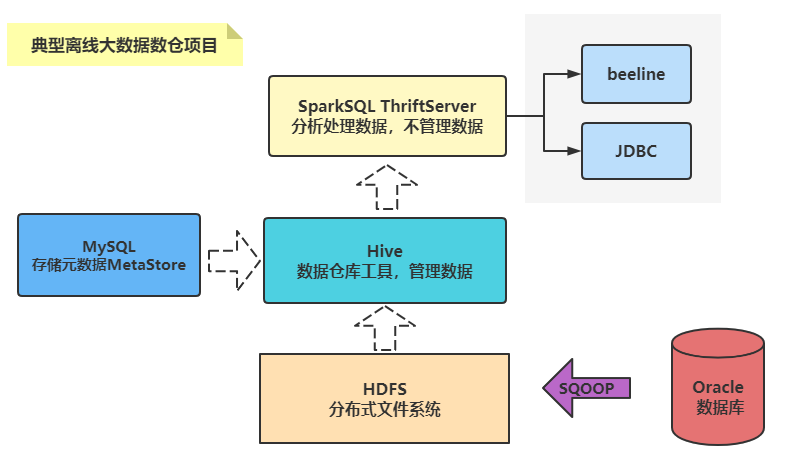
SparkSQL与Hive集成,本质就是Spark Application应用程序,读取加载HiveMetaStore元数据。
database数据库
table表
字段
分区
..... Spark Thrift Server将Spark Applicaiton当做一个服务运行,提供Beeline客户端和JDBC方式访问,与Hive中HiveServer2服务一样的
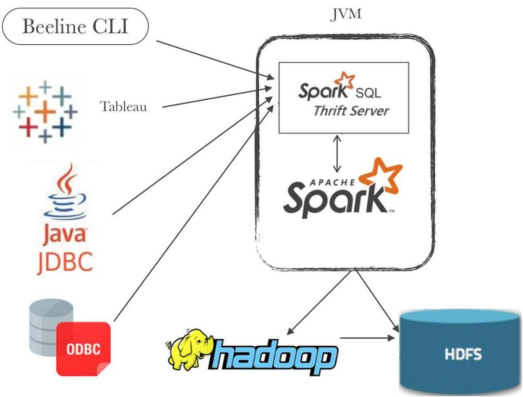
1、启动MySQL数据库
存储Hive 元数据MetaStore
2、启动HiveMetaStore服务
提供提供元数据服务,读取到Hive中管理元数据信息
3、启动HDFS文件系统
Hive表中数据存储在HDFS服务
4、启动Spark Thrift JDBC/ODBC server
将Spark Application当做服务启动,通过JDBC或ODBC方式连接,也可以beeline 命令行连接
编写DDL和DML语句,操作管理数据
与Hive集成,启动服务时,让其连接到HiveMetaStore服务
在SPARK_HOME/conf创建hive-site.xml文件,添加Hive MetaStore地址信息即可。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
</configuration>
启动服务
/export/server/spark/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000 \
--hiveconf hive.server2.thrift.bind.host=node1 \
--master local[2] \
--conf spark.sql.shuffle.partitions=2 \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
5、beeline客户端连接
/export/server/spark/bin/beeline
beeline> !connect jdbc:hive2://node1:10000Spark 内存管理
知识点:Spark Application运行架构
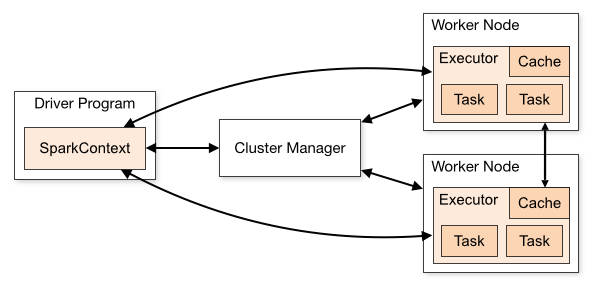
1、Driver Program
创建SparkContext实例对象
申请资源运行Executor、调度Job执行
2、Executors
相当于线程池,里面执行Task任务(以线程方式运行),每个Task任务运行需要1CoreCPU
执行Task任务、缓存RDD数据
每个Executor资源:内存Memeory、CPUCore核数 -> 执行Task任务
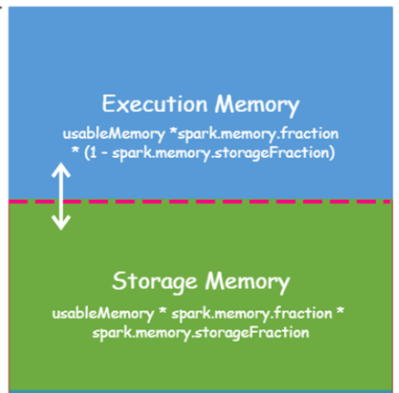
内存Memory主要被用于2个部分:
Task任务执行时,需要内存
Cache缓存数据,需要内存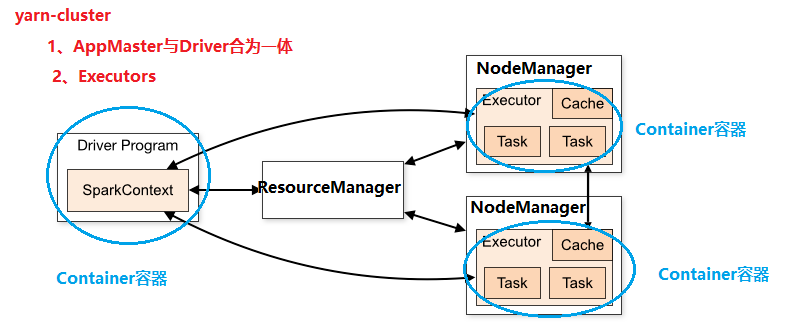
在运行Spark Application时,需要设置如下三个参数:

Executor内存管理,从发展来说,经历2个阶段:
- 1)、Spark 1.6之前,==内存管理【静态内存管理】==
- 直接将内存划分比例,存储Storage内存占比多少和执行Execution内存占比多少,固定死了
- 此种内存管理,存在不合理,比如内存浪费
- 2)、Spark 1.6开始,提供:==统一内存管理(动态内存管理)==,到Spark 2.0时,仅仅支持此种管理方案
- 约定:Storage存储和Execution执行内存占比,默认各占50%

- 动态彼此相互借用
- 如果Storage存储内存不足,但是Execution内存多余,可以借用存储数据,反之亦然
Executor内存划分,包含四个部分,如下图所示:
1、预留内存:300MB
JVM进程自己使用,不允许用户使用
2、可用内存(UsableMemory)
UsableMemory = --executor-memory - 300MB
1)、UserMemory 用户内存
可用内存占比:(1 - spark.memory.fraction) = 0.4
可用内存占比: spark.memory.fraction = 0.6
2)、存储内存
spark.memory.storageFraction = 0.5
3)、执行内存
1- spark.memory.storageFraction = 0.5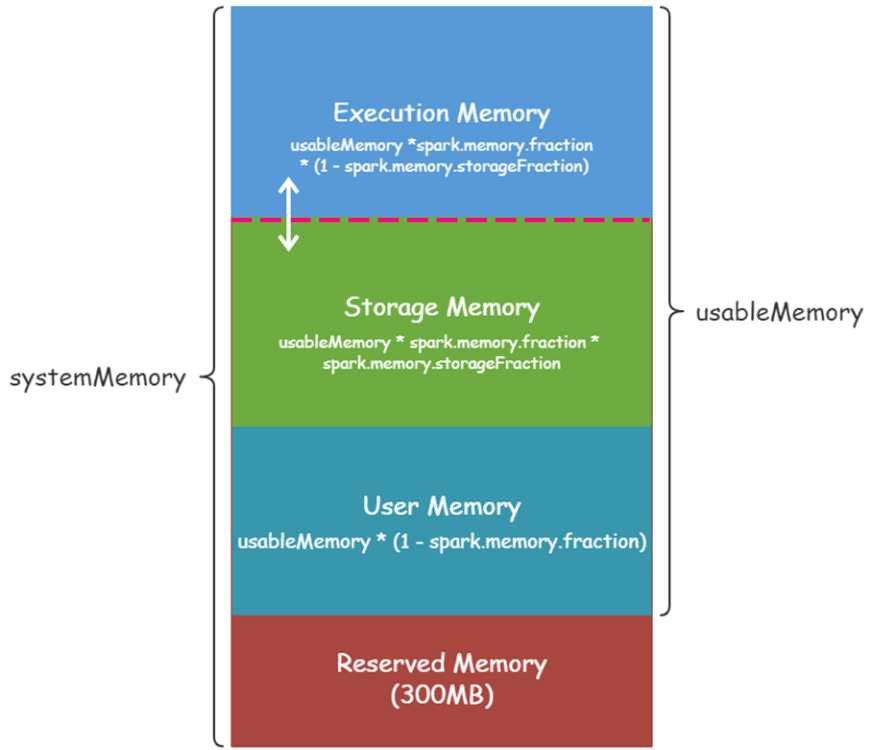
Apache Spark:分布式并行计算框架(三)
https://jface001.github.io/2020/10/03/Spark-Review-Day03/