Apache Spark:分布式并行计算框架(一)
0、前言说明
整理和汇总一下 Spark 容易混淆的概念和理论。
1、Spark 框架概念

Apache Spark™ is a unified analytics engine for large-scale data processing.
1、unified 统一
Spark 框架可以对任意业务需求进行数据分析
批处理:SparkCore、交互式分析:SparkSQL、流式计算:SparkStreaming和StructuredStreaming
图计算:SparkGraphX、机器学习:SparkMLlib
数据科学:PySpark和SparkR
2、 large-scale 大规模
海量数据
类似MapReduce对海量数据处理分析
unified 统一不仅仅是分析,也可以指:Spark 分析数据时,可以时任意数据源
SparkSQL提供一套外部数据源接口,任何数据源只要实现接口,可以读写数据read或write2、Spark与MapReduce相比
面试题:Spark 与MapReduce相比为什么快,有什么不同????
其一、Spark处理数据时,可以将中间处理结果数据存储到内存中;
第二、Spark Job调度以DAG方式,并且每个任务Task执行以线程(Thread)方式,并不是像MapReduce以进程(Process)方式执行。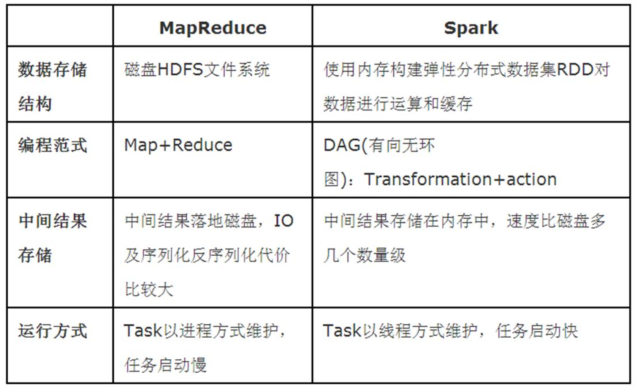
Spark与MapReduce最大不同:提供数据结构RDD弹性分布式数据集。
3、RDD是什么,如何理解
1、RDD是什么,官方定义:不可变、分区的、并行计算的集合,抽象概念

2、每个RDD内部有5个特性
- 分区组成、每个分区被计算处理、依赖一些列RDD
- 可选的:KeyValue类型RDD可以设置分区器,对每个分区数据处理时找到最佳位置(数据本地性)

3、常见RDD,RDD抽象类,泛型,表示具体存储数据类型未知,可以是任何类型。
1、HadoopRDD,表示从文件系统加载数据封装的集合
2、MapPartitionsRDD,表示经过转换后的,比如fliter、map、flatMap等
3、ShuffleRDD,表示对RDD数据进行处理,产生shuffle时RDD4、RDD、DataFrame和DataSet区别
1、RDD是啥??
不可变、分区的、并行计算基本
2、DataFrame
DataFrame = RDD[Row] + Schema(字段名称、字段类型)
知道内部结构
当在处理分析数据,由于知道内部结构,所以可以先进行优化,在计算分析数据
3、Dataset
Spark 1.6诞生
Dataset = RDD + Schema
知道内部结构,也知道外部结构,编程更加安全和方便,内部数据存储使用特殊编码方式,节省空间
4、Spark 2.0开始
DataFrame和Dataset合并,其中DataFrame时Dataset特殊形式,数据类型为Row时数据结构
DataFrame = Dataset[Row]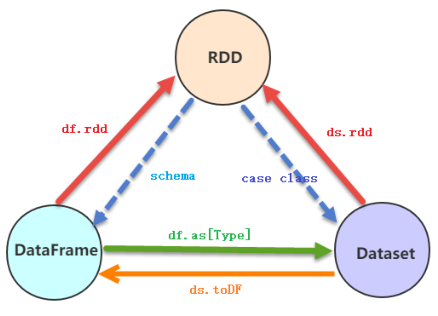
从Spark 2.x开始,建议大家使用数据结构为Dataset/DataFrame,因此使用SparkSQL模块分析数据。
5、Spark on YARN执行流程
将Spark 应用程序(无论批处理还是流计算),提交运行到YARN集群上,提交流程。
Spark Application运行有2种DeployMode:
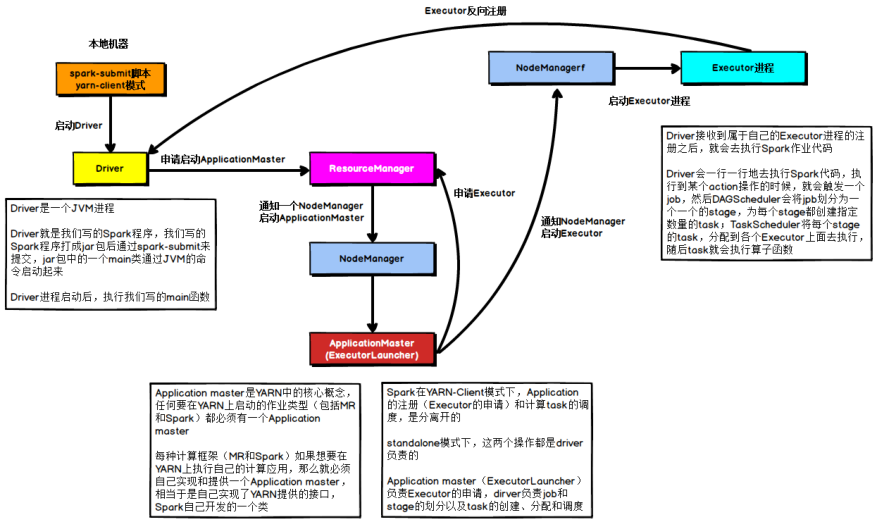
1、client客户端
DriverProgram运行在提交运行客户端主机上
- DriverProgram,调度Job执行
- AppMaster,运行在NM中容器,申请资源运行Executors
- Executors,运行在NM中容器,执行Task任务和缓存数据
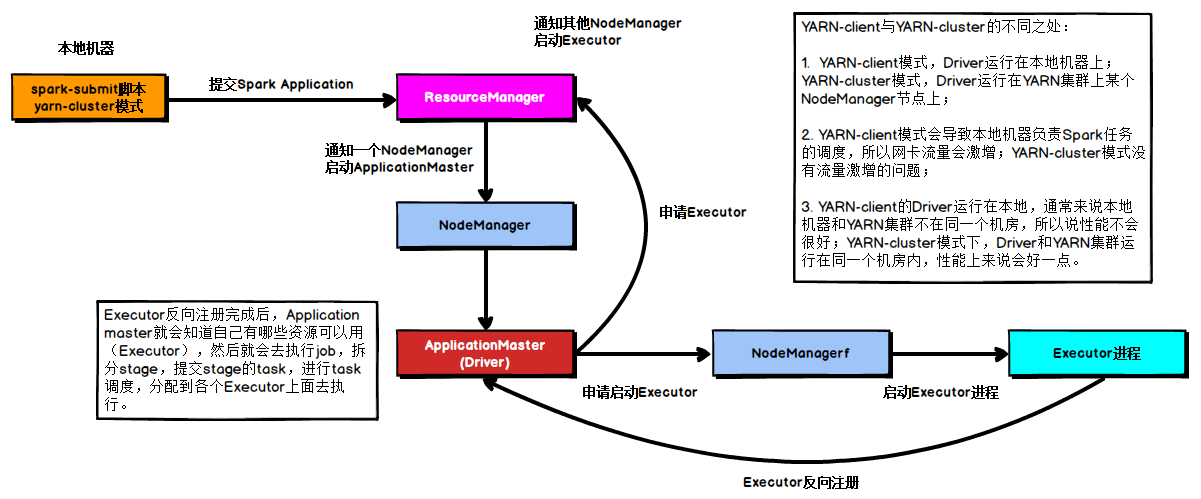
2、cluster集群
DriverProgram运行在YARN集群NodeManager容器中
- AppMaster/DriverProgram,运行在NM中容器,申请资源运行Executors和Job调度执行
- Executors,运行在NM中容器,执行Task任务和缓存数据
yarn-client,测试使用
yarn-cluster,生成环境运行方式

6、SparkJob调度过程
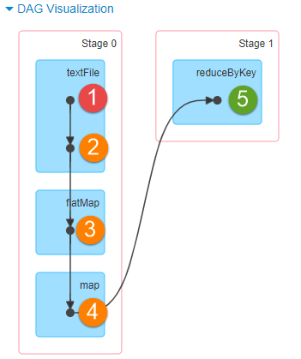
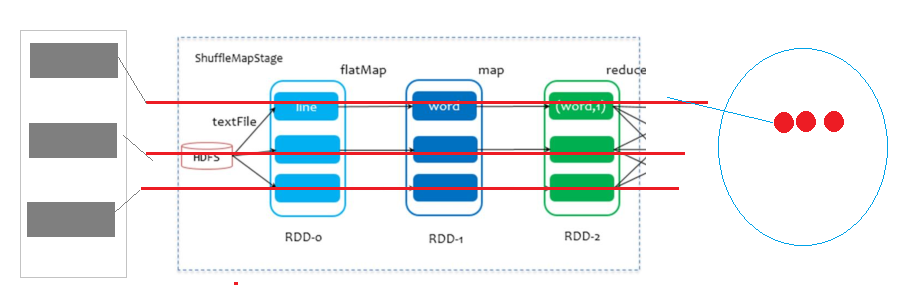
词频统计WordCount程序执行DAG图
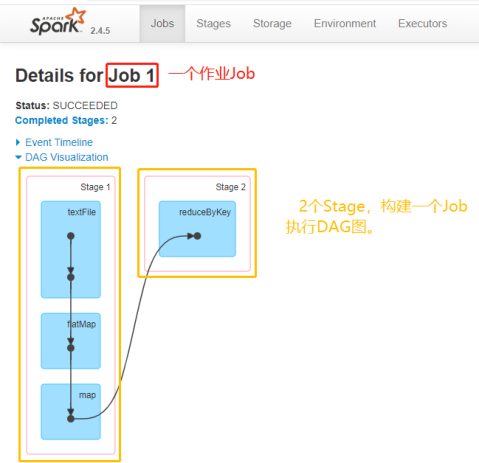
1、RDD#Action函数,触发一个Job执行
count、foreach、foreachPartition等等
2、第一步、构建DAG图
从触发Job开始RDD,采用回溯法(倒推法,从后向前),依据RDD依赖关系,构建Job对应DAG图
【依赖、回溯法】
3、第二步、划分DAG图为Stage
从触发Job开始RDD,采用回溯法,如果2个RDD之间依赖为宽依赖,划分后面为一个Stage,依次类推
DAGScheduler
划分完成以后,此时每个Job由多个Stage组成,各个Stage之间相互依赖关系
后面的Stage处理前面Stage的数据
相邻2个Stage之间产生Shuffle
Stage划分为2种类型:
第一、ResultStage,产生Result结果,每个Job中最后一个Stage
第二、ShuffleMapStage,除去Job中最后一个Stage其他Stage都是
4、第三步、按照Job中Stage顺序,从前向后执行Stage中Task任务
每个Stage中有多个Task任务,逻辑相同,处理数据不同而已
将Stage中Task任务打包为TaskSet,发送给Executor执行
TaskScheduler
问题1:每个Stage中Task数目如何确定??
由Stage中最后一个RDD分区数目确定
问题2:每个Stage中Task任务计算模式是什么????
管道计算模式,Pipeline模式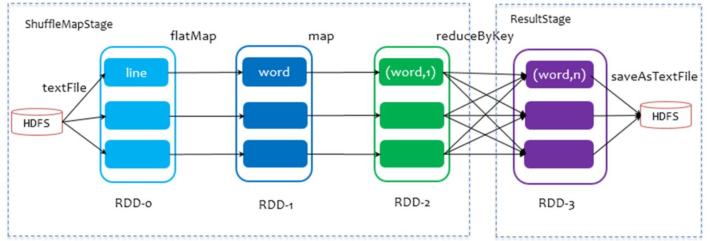
package cn.test.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkContext.getOrCreate(
new SparkConf().setMaster("local[1]").setAppName("SparkWordCount")
)
val inputRDD: RDD[String] = sc.parallelize(
Seq("111111111111111111", "222222222222222222", "3333333333333333333"), numSlices = 2
)
println(s"RDD 分区数目:${inputRDD.getNumPartitions}")
val resultRDD: RDD[String] = inputRDD
.filter(line => {
println("filter........................")
// 直接返回
true
})
.flatMap(line => {
println("flatMap........................")
Seq(line)
})
.map(line => {
println("map........................")
line
})
/*
filter........................
flatMap........................
map........................
filter........................
flatMap........................
map........................
filter........................
flatMap........................
map........................
*/
val count = resultRDD.count()
println(s"Count = ${count}")
}
}
7、Spark中依赖类型
主要RDD依赖分为2类:
- 窄依赖:1对1,父RDD1个分区数据对应子RDD1个分区数据
宽依赖:1对多,父RDD1个分区数据对应子RDD多个分区数据
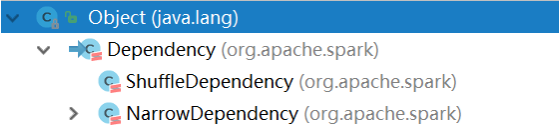
宽依赖:Shuffle依赖
相邻RDD产生Shuffle
Spark Shuffle 分为2个部分:
1、Shuffle Writer(上游Stage产生)
将Shuffle数据写磁盘,有3种方式,具体由底层自动选择
2、ShuffleReader(下游Stage产生)
读取Shuffle到磁盘中数据,进行处理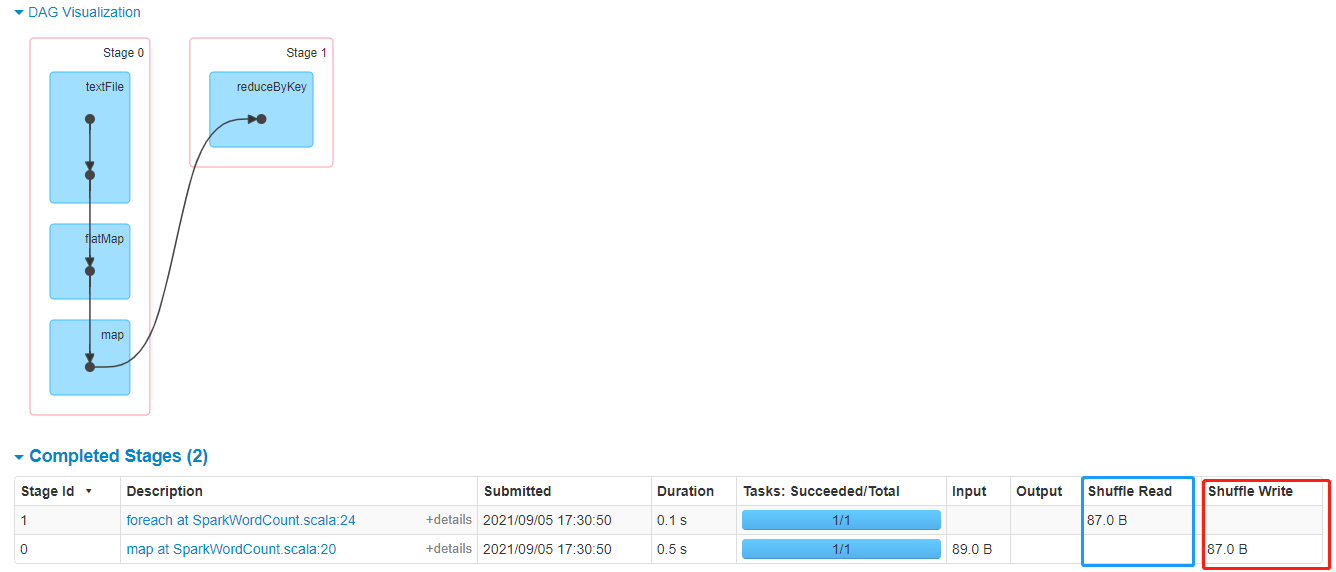
Apache Spark:分布式并行计算框架(一)
https://jface001.github.io/2020/09/22/Spark-Review-Day01/